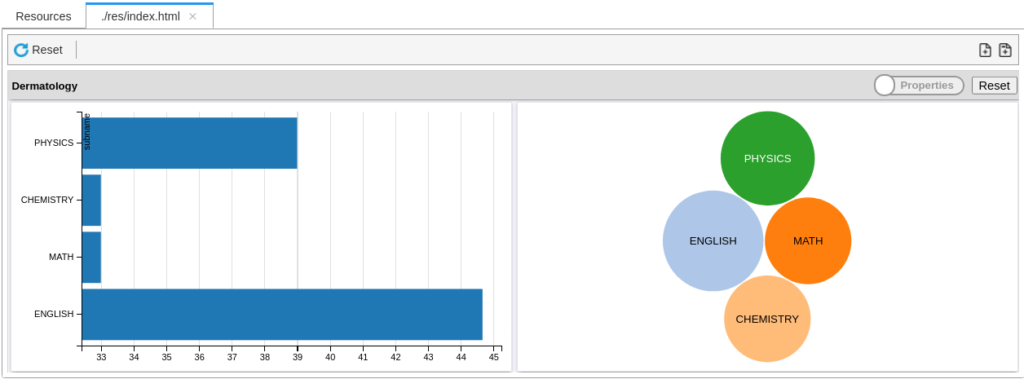
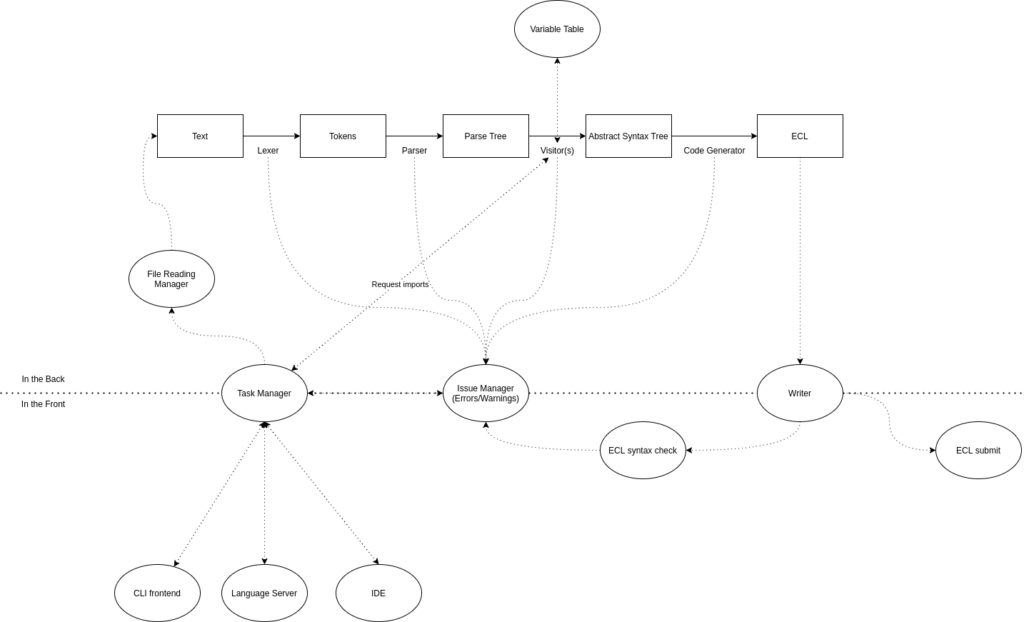
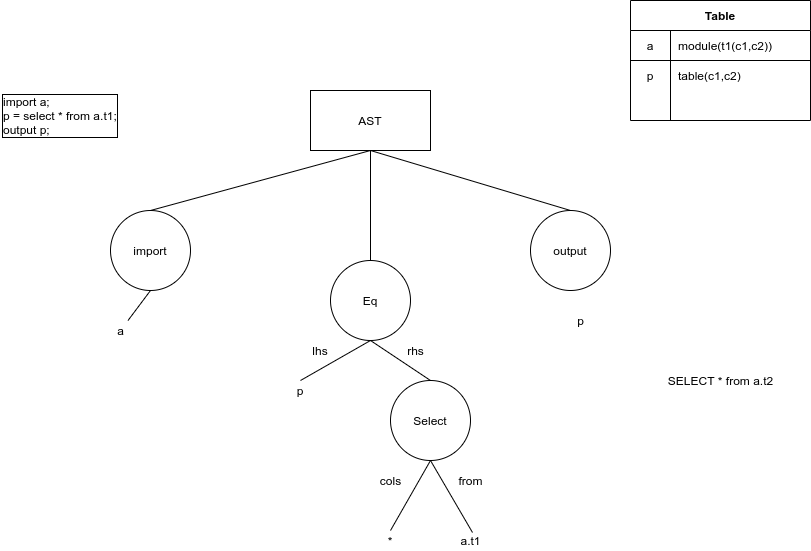
This week’s work was on getting the WRITE statement to work, and extending a DISTRIBUTE extension to SELECT. The rest, was getting some bugfixes and reading.
Write
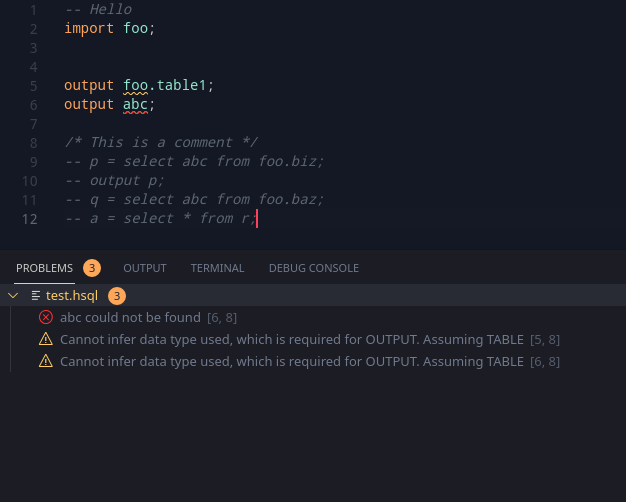
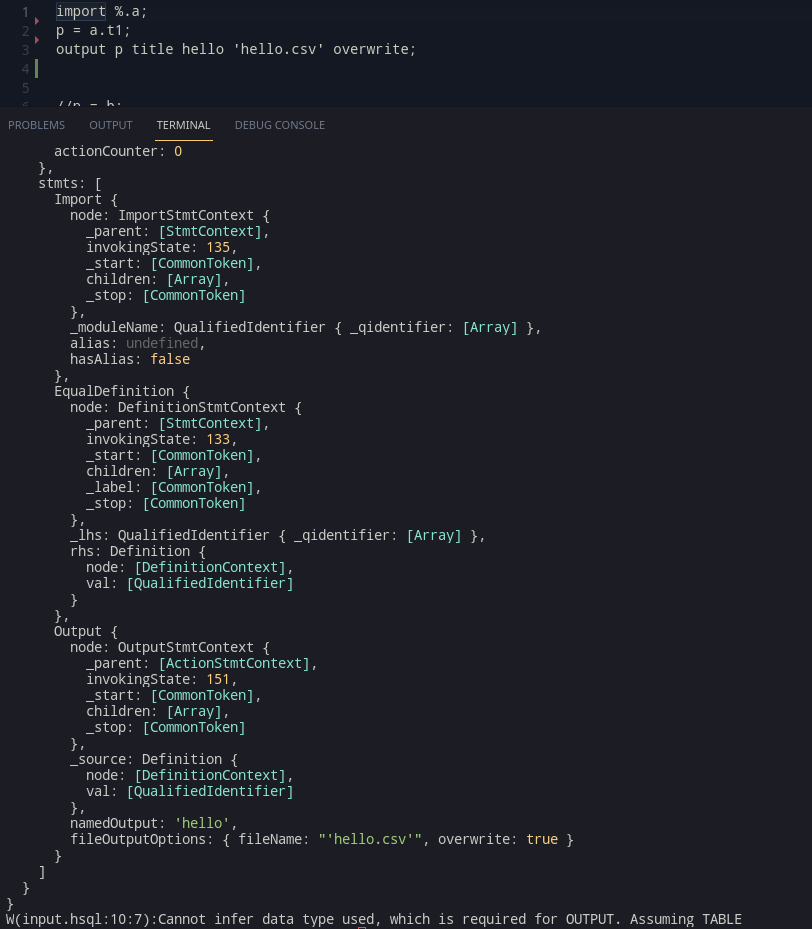
The OUTPUT statement in HSQL is intended to be a way to output values to a workunit. In ECL however, OUTPUT can be used to write to a workunit as well as to a logical file. In HSQL, it is better to bifurcate the process into two separate commands. With this, the idea behind the WRITE statement, is to allow writing datasets into the logical file.
The syntax for WRITE was designed as:
WRITE <id> [TO [FILE]] [TYPE] [JSON|THOR|CSV|XML] <STRING> [OVERWRITE];ECL can support outputs of 4 types – ECL, JSON, THOR, CSV. Typescript enums are a great way of supporting this:
export enum FileOutputType {
THOR,
CSV,
JSON,
XML,
}
// get the enum value
const y = FileOutputType.THOR;
// y is 0
// get the string
const z = FileOutputType[y];
// z is 'THOR'The enums provide a two way string and integer conversion; which is convenient for storing the two representations while still being good computationally.
Adding in the AST and Code generation stages, we can test out some examples:
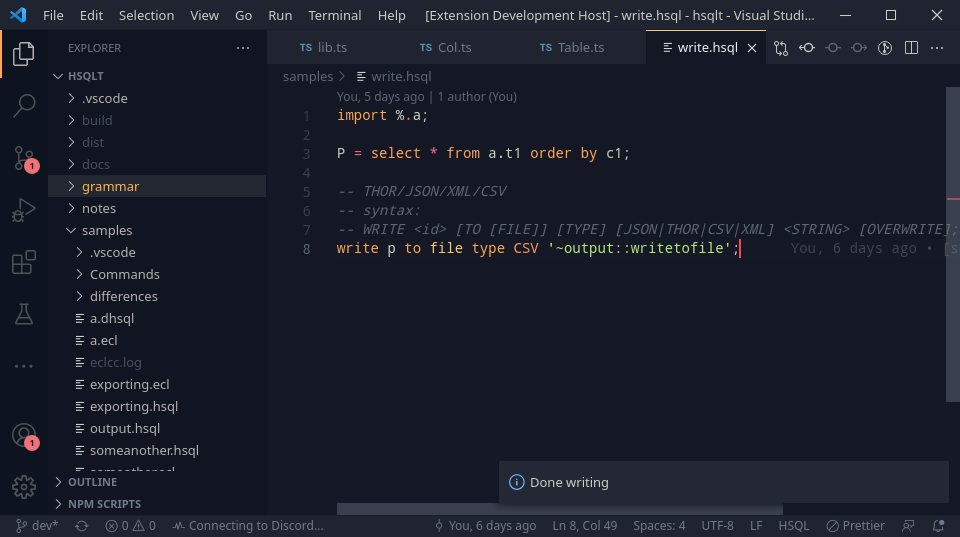
-- hsqlt make Commands/write_command/write.hsql
import %.a;
P = select * from a.t1 order by c1;
-- THOR/JSON/XML/CSV
-- syntax:
-- WRITE <id> [TO [FILE]] [TYPE] [JSON|THOR|CSV|XML] <STRING> [OVERWRITE];
write p to file type CSV '~output::writetofile.csv';
-- to thor files
write p to file type THOR '~output::writetofile.thor';
-- to xml
write p to file XML '~output::writetofile.xml';This gives a nice way to write files to output so they can be used outside too.
DISTRIBUTE extension of SELECT
DISTRIBUTE in ECL is used to distribute data across nodes, for further computation; it is really helpful for managing data skew as we go along with further computations.
The idea for it is to be added as an extension in the HSQL select statement with the grammar being:
DISTRIBUTE BY <col1>[,<col2>,...]This will add a DISTRIBUTE element to the end of the SELECT pipeline which will aid in managing data skew.
a = select * from marksmodule.marksds where marks>40 distribute by marks,subid;The output for this expression looks like this:
__r_action_0 := FUNCTION
__r_action_1 := marksmodule.marksds( marks > 40);
__r_action_2 := TABLE(__r_action_1,{ __r_action_1 });
__r_action_3 := DISTRIBUTE(__r_action_2,HASH32(marks,subid));
RETURN __r_action_3;
END;
aa := __r_action_0;The __r_action_3 is a computation that obtains the distributed definition and this is returned in that context. HASH32 has been recommended for use as per the documentation when distributing by expressions/columns, and was chosen as it would be the most used way of distributing that still maintains even distribution.
Bugfixes for the extension
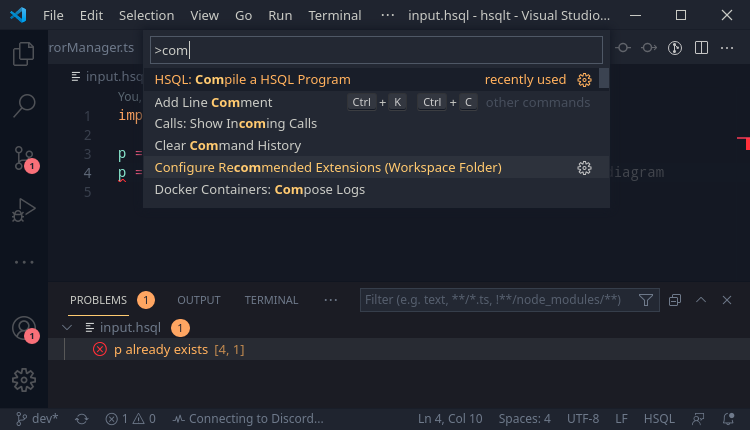
Seems like the extension was lagging behind HSQLT. This is from the previous update that added in the file system reading. As the file locations have to now be provided separately, the Extension had not yet been configured for it. Additionally, the extension’s client and servers work on different folders. Due to this, the server can successfully locate files, whereas the client fails to. This required support for the compiler to refer to another directory ‘offset’ from the current directory (This has been added to the CLI tool as a -b flag).
Adding this and support for %, allows HSQL to be used with the extension a bit more easily.
Demo
As there was a demo that was done at the end of this week, various examples have been created to show how HSQL may be used. Currently, they do not showcase actual usecases, but only the syntax and the usability of the language. Nearly all supported features have been enumerated and the plan is to have a nice set of examples for each statement going ahead. The demo actually revealed some good to have feedback and the plan is to work towards getting some more statements and features as we go along.
Wrapping up
As Week 7 is coming to wraps, the plan is to work on these for Week 8:
- Add support for exporting definitions
- Add support for bundling definitions into modules in HSQL
- Look into procedure syntaxes in HSQL
- Evaluate existing featureset and make some examples to work on performance and correctness.