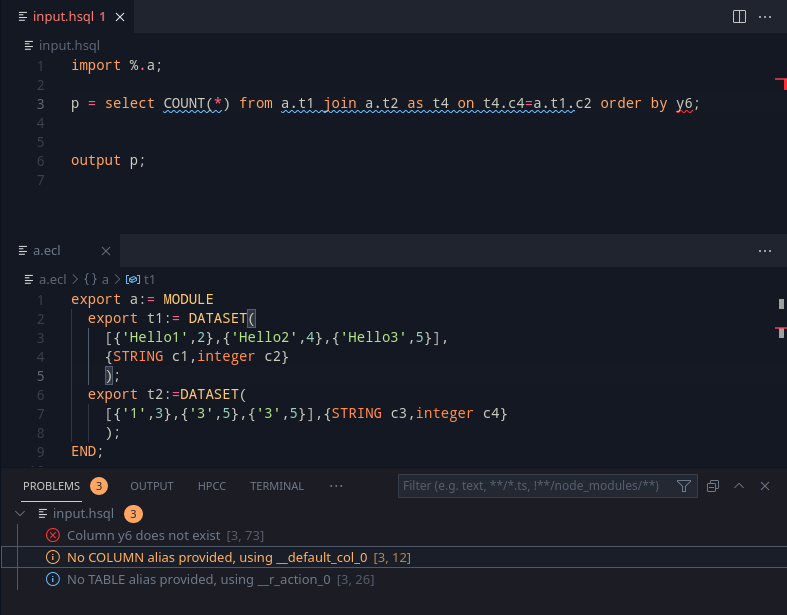
This week was focused on creating EXPORT/SHARED to work, and to add over importing from current directory and Layouts.
Exports
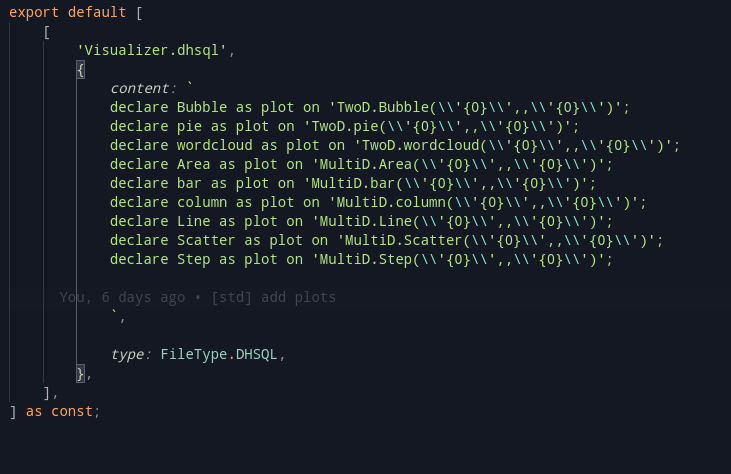
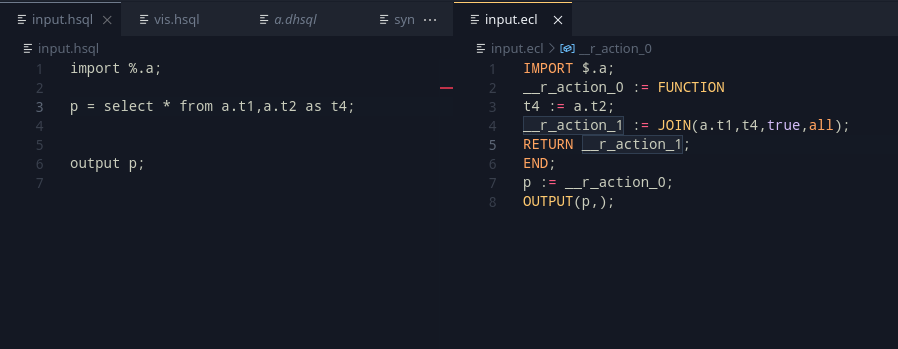
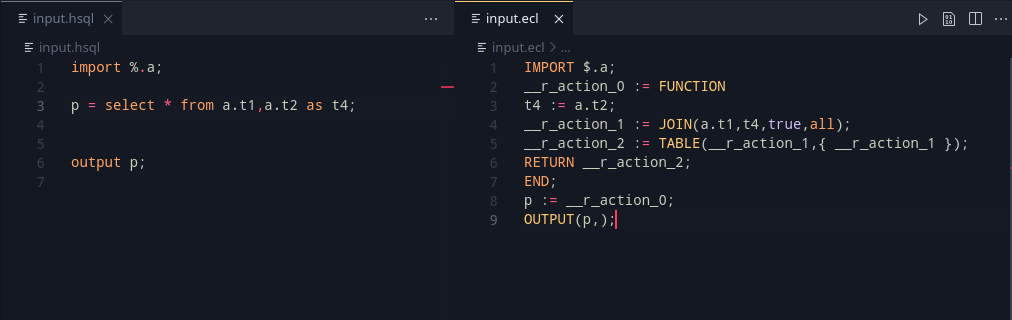
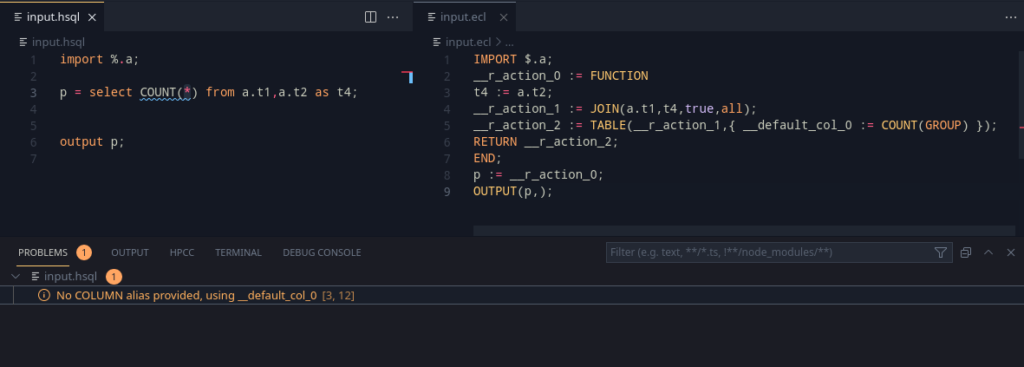
Exports are a very useful feature in any language. The main idea here is to export some data and layouts, that can be reused in another module. Taking a piece from ECL, we can define two such export modes: SHARED and EXPORT. Let’s take a look at the example below:
export x = select * from table1;
export y = select * from table2;This should export out x and y so that it may be used outside. A key note to be made is that unlike ECL, the export <filename> := MODULE should autowrap the program.
There are two possible ways of solving this. One is to write a visitor that can decide whether there is a need to export the module, or we can offload the work to the parser, using a grammar action.
Consider the following simplified grammar:
program: (stmt SEMICOLON)* EOF;
...
stmt:= scope IDENTIFIER '=' expr;
scope: EXPORT|SHARED|;This above grammar accepts a scoped definition. Instead of doing the computation on the visitor/AST Generation side, we can use locals to get this value by the end of the parsing process itself.
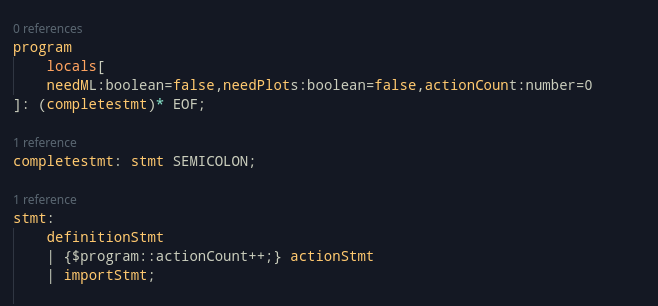
program locals[willExport:boolean=false]: (stmt SEMICOLON)* EOF;
...
stmt:= scope IDENTIFIER '=' expr;
scope: EXPORT { $program::willExport:boolean=true} | SHARED { $program::willExport:boolean=true} |;This is a quick and easy way to set the program to decide whether it will be wrapped as a module.
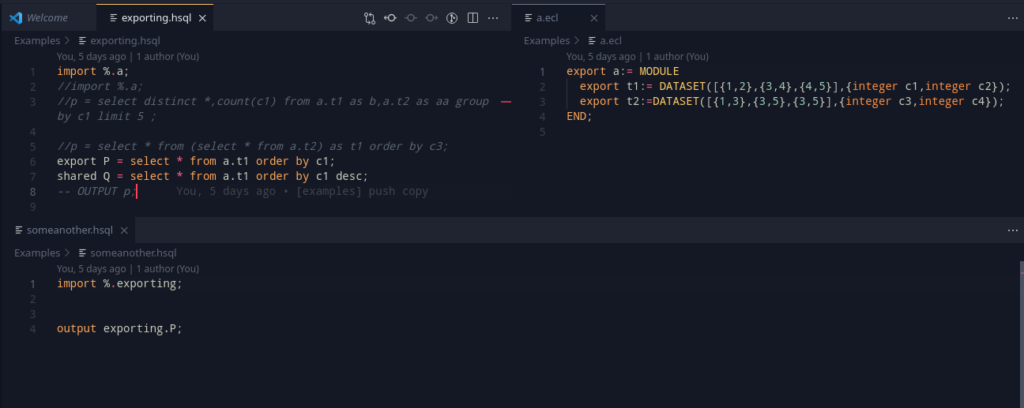
Proceeding further with this, this setup does yield an interesting use – since the variable names in an exported ECL module is the same as that of the window, we can actually import translated hsql files from an ECL file and use it the same way!
Imports from the current directory
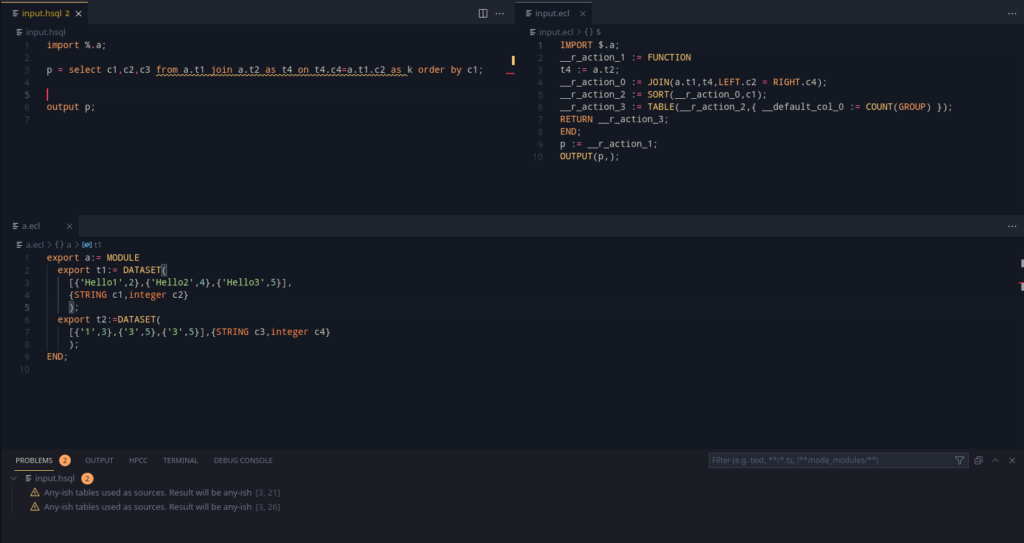
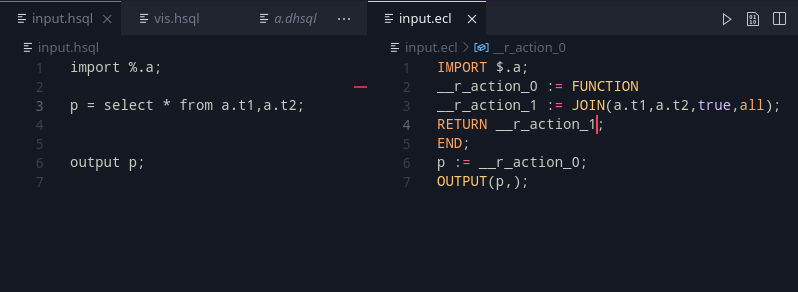
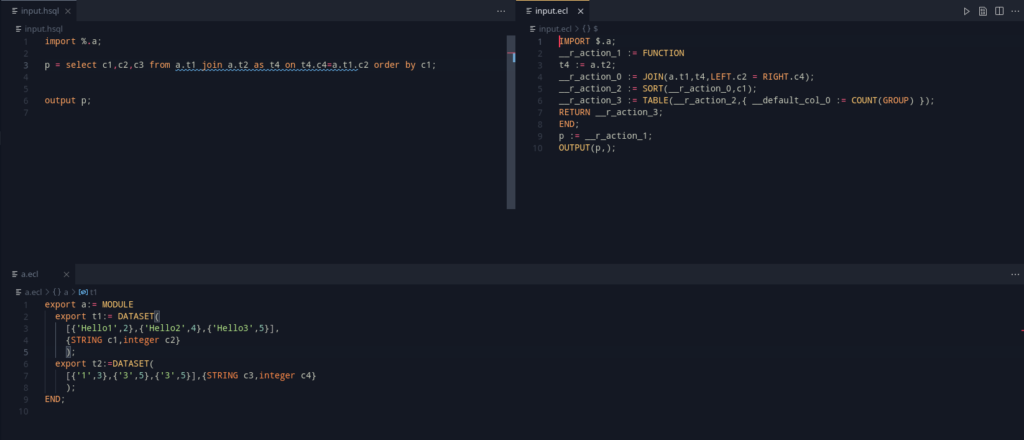
ECL has a $ operator which can be used in imports to refer to the current directory. Although grammar support has been there for it in HSQL, the compiler would read and only use the % operator (which performs the work of the $ operator from ECL) as an indication for whether the standard libraries could be skipped or not.
This implementation requires proper file location information is passed into the AST Generator, which allows us to Import modules as required. This also adds support for detecting cyclic imports (which are not allowed in ECL either). This can be added in via the presence of an include stack.
The idea of an include stack, is to present a stack, where the top of the stack will represent the current file being processed. Once this is over, the file is popped. Hence, to detect an include cycle, it is trivial to check if the file is already present in the current include stack.
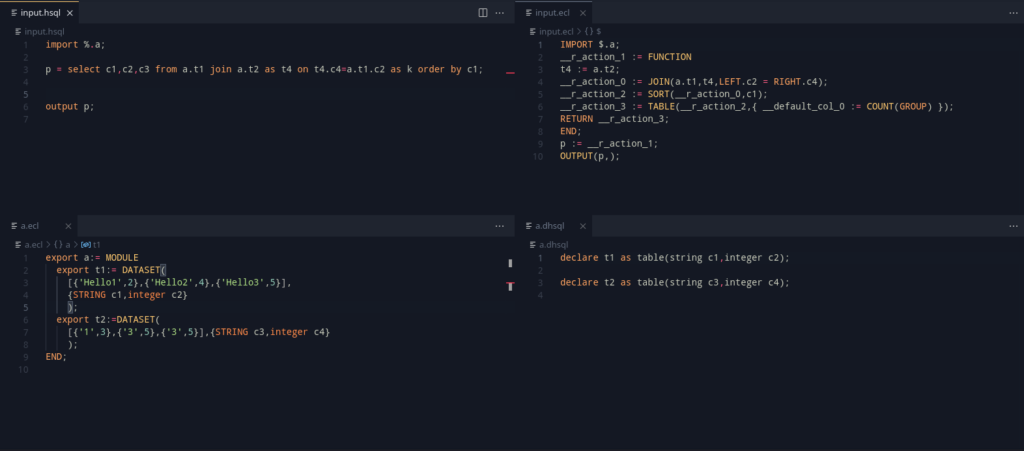
Adding all this in, we get a nice example that summarizes the work:
Layouts
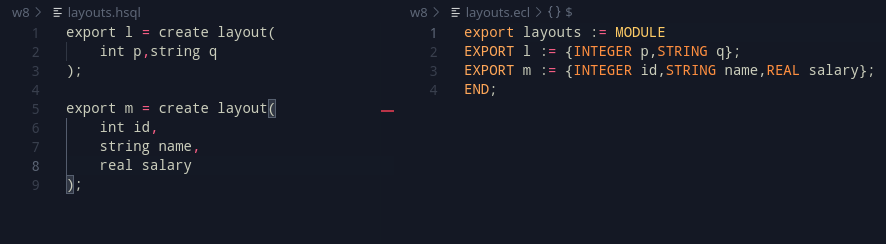
From here, the work shifted onto layouts. Although not explicitly a goal, layouts are an important precursor to functions and for select. Looking at the syntax of the CREATE TABLE syntax in SQL, we can work with and add a layout with an example syntax as:
x = create layout(
int p, string q
);The data type is kept in the front to allow people from other languages to be familiar with it (Hint: C/C++/C#/Java/JS)
Internally, a layout represents a RECORD. After adding them in, they look somewhat like this:
Layouts are represented in the Variable Table (Commonly referred as symbol tables in usual compiler terminology) as their own separate term, and can be used to create tables. This, is actually thankfully trivial as the contents of a layout are identical to that of a table, Col elements. With a deep clone of its children, we can create a corresponding table. This will come in use as more features get added into the language.
Wrapping up for the big week ahead
There were some key precursor elements that were made this week, and the syntaxes of Module and Function have been defined, and the idea is to start working on them from here on out. The rough plan for next week is-
- Work with layouts
- Add in modules
- Add in support for functions
- Prepare some more examples for showing the functionality of HSQL.